remotes::install_github("lme4/lme4", dependencies = TRUE)12 Repeated measures mixed models
Warning
THIS CHAPTER IS A WORK IN PROGRESS PARTICULARILY WITH RESPECT TO LME4 v2.0 COVARIANCE STRUCTURES. IT’S UNCLEAR IF THESE WORK WITH ‘lmerTest’. ADDITIONALLY, THERE ARE SOME WEIRD ESTIMATION ISSUES: OVERALLY HIGH VALUES FOR ‘PHI’ WHEN USING AR1, SOME WILD SWINGS IN THE LOG LIKELIHOOD AND NON-PD VARIANCE COMPONENTS THAT STYMIE ‘emmeans’.
12.1 Background
In the previous chapters, we have covered how to run linear mixed models for various experimental designs. All the examples in those chapters were independent measure designs, where each subject was assigned to a different treatment. Now we will move on to experiment with repeated measures effects (also called “longitudinal data”).
Studies that involve repeated data collection from the same experimental units (or subjects) requires a repeated measures component in analysis to model correlations across time for each subject. This is common in studies that are evaluated across different time periods. For example, if samples are collected over different time periods from the same subject or experimental unit, we must model the repeated measures covariance structure when analyzing the treatment effects.
In these models, the ‘iid’ assumption (independently and identically distributed) is often violated, so we need to introduce specialized covariance structures that can account for these correlations between error terms.
For this these models, we will use ‘nlme’ and ‘lme4’. These packages provide well documented implementations of heterogeneous error structures. Another package, mmrm, does provide functionality for repeated measures for limited experimental designs, but we will not be exploring that due to limitations in implemented models. Until recently, implementing hetergenous error terms was quite challenging in lme4. Starting with version 2.0 of lme4, functionality for implementing some covariance structures is available. You may need to download the latest development version of ‘lme4’ to access the latest functionality:
The package glmmTMB (generalized linear mixed model using the template model builder) will also implement many covariance structures and despite its name, can work fine with general linear models (Gaussian) and does not require a mixed component. The implemented structures include compound symmetry, AR1, toeplitz, unstructured and several spatial covariance structures. Truly, this package is incredible.
In this chapter, we will analyze data from different experiment designs with repeated measures including randomized complete block design, split-plot, and split-split plot designs.
There are several types of covariance structures:
| Structure name | nlme function | lme4 function |
|---|---|---|
| Autoregressive (AR1) | corAR1() |
ar1() |
| Compound symmetry | corCompSymm() |
cs() |
| Unstructured | CorSymm() |
us() |
To read more about selecting appropriate covariance structure based on your data, please refer to this SAS guide.
The repeated measures syntax in nlme follow this convention:
corAR1(value = 0, form = ~ t|g, fixed = FALSE).
The argument for value is the starting value for iterations (zero is the default), and if fixed = FALSE (the current nlme default), this value will be allowed to change during the model fitting process. The argument structure for form, ~ t|g, where \(t\) is the temporal variable and \(g\) is the grouping factor (the subject or experimental unit) to estimate covariance across. Technically, \(g\) is optional and if not specified, the order of the data set will be assumed \(t\). However, for most replicated experiments, you will need to specify \(g\). When we use ~t|g form, the correlation structure is supposed to apply only to observations within the same grouping level. The covariate for this correlation structure must be an integer value. Similarly, corCompSymm() and corSymm() follow the same argument syntax.
There are other covariance structures enabled by ‘nlme’ (e.g., corARMA(), corCAR1()), but we have found that corAR1() and corCompSymm() work for most circumstances. Read the nlme manual if you want to learn more about covariance structures available in that package.
13 Examples
let’s start with loading the required libraries for this analysis.
library(nlme); library(performance); library(emmeans)
library(dplyr); library(broom.mixed); library(ggplot2)library(lme4); library(performance); library(emmeans)
library(dplyr); library(broom.mixed); library(ggplot2)13.1 RCBD Repeated Measures
First, we will start with the first example with randomized complete block design with repeated measures.
The data for this example are a sorghum trial, arranged in a RCBD with five replications and 4 levels of the treatment, ‘variety’. The dependent variable, ‘y’ (leaf are index) was measured weekly for 5 weeks. This data set was originally described by Milliken and Johnson (2009).
We need to have time as both a numeric and a factor variable for the modeling packages. The variable ‘week’ is formatted as a factor (“factweek”) for estimating the effect of each week. For the repeated measures structure, the numeric variable ‘week’ is used. Since variety and block imported as numeric, they are converted to character variables.
sorghum <- read.csv(here::here("data", "sorghum.csv")) |>
mutate(block = as.character(block),
factweek = as.character(week),
plot = as.character(plot),
variety = as.character(variety))| block | blocking unit |
| week / factweek | Time points when data was collected |
| plot | plot (experimental unit) |
| variety | treatment factor, 4 levels |
| y | leaf area index |
13.1.1 Data Integrity Checks
Let’s do preliminary data check including evaluating data structure, distribution of treatments, number of missing values, and distribution of response variable.
- Check structure of the data
str(sorghum)'data.frame': 100 obs. of 6 variables:
$ block : chr "1" "1" "1" "1" ...
$ week : int 1 2 3 4 5 1 2 3 4 5 ...
$ plot : chr "1" "1" "1" "1" ...
$ variety : chr "1" "1" "1" "1" ...
$ y : num 5 4.84 4.02 3.75 3.13 4.42 4.3 3.67 3.23 2.83 ...
$ factweek: chr "1" "2" "3" "4" ...In this data set, ‘block’, ‘plot’, and ‘factweek’ are characters, while ‘y’ and ‘week’ are coded as numeric.
- Inspect the independent variables
table(sorghum$variety, sorghum$block)
1 2 3 4 5
1 5 5 5 5 5
2 5 5 5 5 5
3 5 5 5 5 5
4 5 5 5 5 5The cross tabulation shows a equal number of variety treatments in each block.
- Check the extent of missing data
colSums(is.na(sorghum)) block week plot variety y factweek
0 0 0 0 0 0 No missing values
- Inspect the dependent variable
ggplot(data = sorghum, aes(y = y, x = factweek, fill = variety)) +
geom_boxplot() +
theme_bw()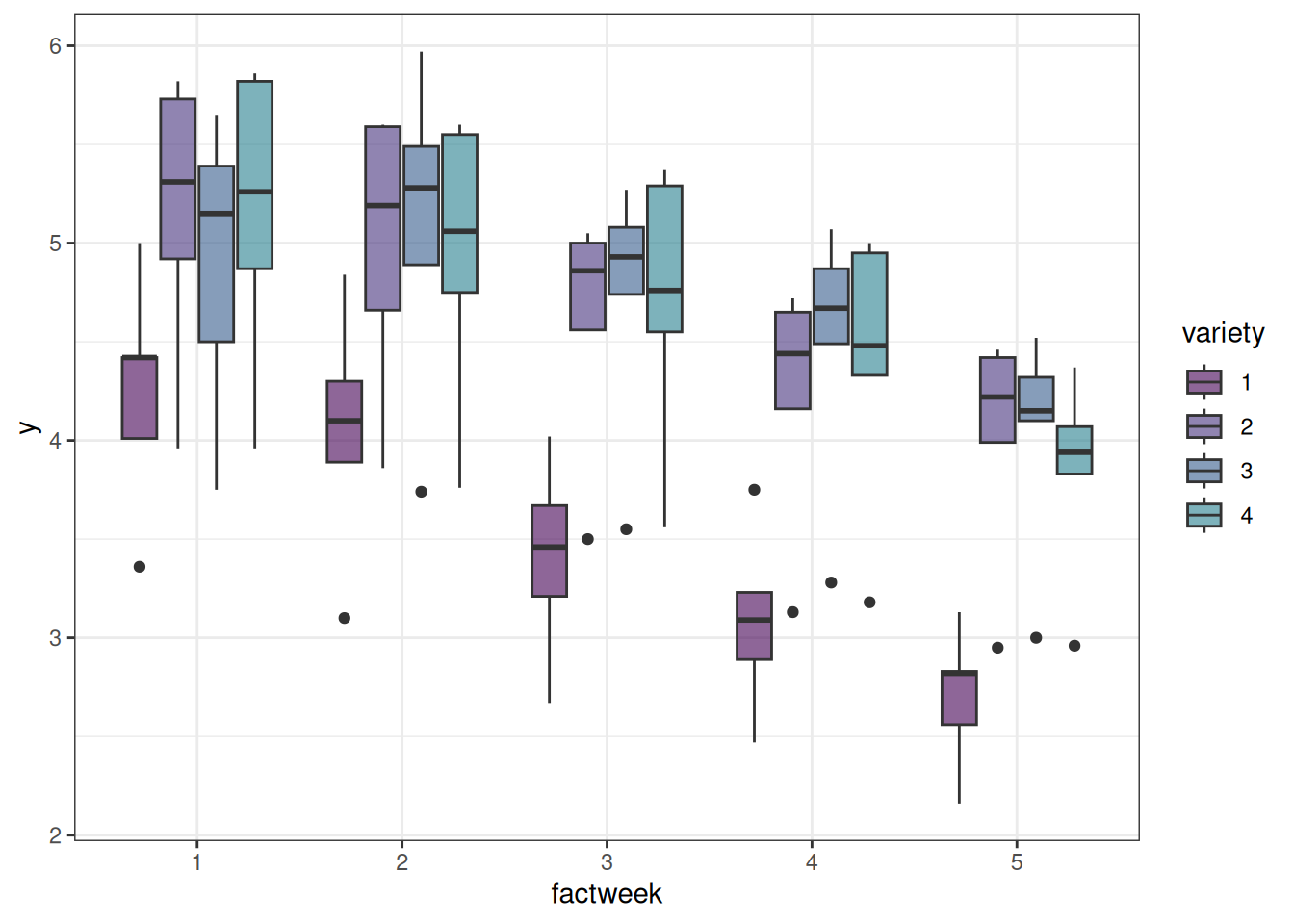
It loooks like variety ‘1’ has the lowest yield and showed drastic reduction in yield over weeks compared to other varieties.
One last step before we fit model is to look at the distribution of response variable.
hist(sorghum$y, main = NA, xlab = "leaf area index")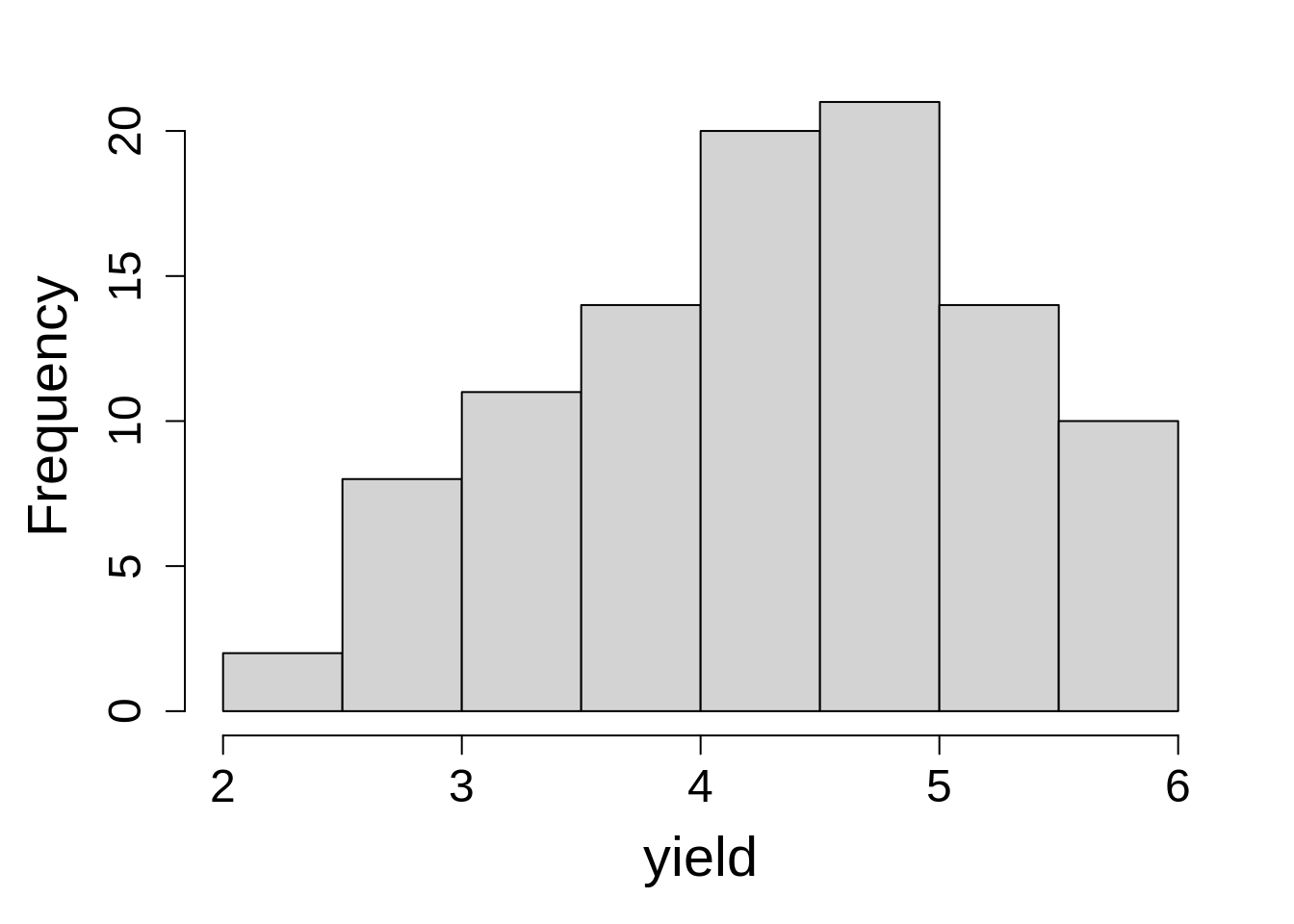
13.1.2 Model Building
Let’s fit the model first using lme() from the nlme package. A full specified model is fit and ‘plot’ is nested within ‘block’.
sorg_1a <- lme(y ~ variety + factweek + variety:factweek,
random = ~1|block/plot,
data = sorghum,
na.action = na.exclude)sorg_2a <- lmer(y ~ variety + factweek + variety:factweek + (1|block/plot),
data = sorghum,
na.action = na.exclude)The model fitted above doesn’t account for the repeated measures effect. To account for the variation caused by repeated measurements, correlation among responses can be modelled for a given subject, which is a plot (factor variable) in this case.
By adding this correlation structure, we are accounting for variation caused by repeated measurements over weeks for each plot. The AR1 structure assumes that data points collected more proximately are more correlated. Whereas, the compound symmetry structure assumes that correlation is equal for all time gaps. Here, we will fit a model with both correlation structures and compare models to find out the best fitting model.
In this analysis, the time variable is week, and it must be numeric.
In the code chunks above, we fitted two correlation structures including AR1 and compound symmetry matrices. Next we will update the model object separately with each correlation matrix.
cs1 <- corAR1(form = ~ week|block/plot, value = 0.2, fixed = FALSE)
cs2 <- corCompSymm(form = ~ week|block/plot, value = 0.2, fixed = FALSE)
sorg_1b <- update(sorg_1a, corr = cs1)
sorg_1c <- update(sorg_1a, corr= cs2)sorg_2b <- lmer(y ~ variety + factweek + variety:factweek + ar1(0 + week|block/plot),
data = sorghum, na.action = na.exclude)boundary (singular) fit: see help('isSingular')sorg_2c <- lmer(y ~ variety + factweek + variety:factweek + cs(1 + week|block/plot),
data = sorghum, na.action = na.exclude)The model using an AR1 structure, ‘sorg_2b’, drew the warning boundary (singular) fit: see help('isSingular') because the variance estimate for ‘block’ is nearing zero due to the plot and the AR1 covariance structure effectively modelling spatial variation. We can refit the model without ‘block’.
sorg_2d <- lmer(y ~ variety + factweek + variety:factweek + ar1(0 + week|plot),
data = sorghum, na.action = na.exclude)PHI IS 1.00???
sorg_2bLinear mixed model fit by REML ['lmerMod']
Formula: y ~ variety + factweek + variety:factweek + ar1(0 + week | block/plot)
Data: sorghum
REML criterion at convergence: 118.5216
Random effects:
Groups Name Std.Dev. Corr
plot:block week 0.0000 1.00 (ar1)
block week 0.0000 1.00 (ar1)
Residual 0.3778
Number of obs: 100, groups: plot:block, 20; block, 5
Fixed Effects:
(Intercept) variety2 variety3 variety4
4.242 0.906 0.646 0.912
factweek2 factweek3 factweek4 factweek5
-0.196 -0.836 -1.156 -1.542
variety2:factweek2 variety3:factweek2 variety4:factweek2 variety2:factweek3
0.028 0.382 -0.014 0.282
variety3:factweek3 variety4:factweek3 variety2:factweek4 variety3:factweek4
0.662 0.388 0.228 0.744
variety4:factweek4 variety2:factweek5 variety3:factweek5 variety4:factweek5
0.390 0.402 0.672 0.222
optimizer (nloptwrap) convergence code: 0 (OK) ; 0 optimizer warnings; 1 lme4 warnings sorg_2dLinear mixed model fit by REML ['lmerMod']
Formula: y ~ variety + factweek + variety:factweek + ar1(0 + week | plot)
Data: sorghum
REML criterion at convergence: 147.2443
Random effects:
Groups Name Std.Dev. Corr
plot week 0.1615 1.00 (ar1)
Residual 0.3935
Number of obs: 100, groups: plot, 20
Fixed Effects:
(Intercept) variety2 variety3 variety4
4.242 0.906 0.646 0.912
factweek2 factweek3 factweek4 factweek5
-0.196 -0.836 -1.156 -1.542
variety2:factweek2 variety3:factweek2 variety4:factweek2 variety2:factweek3
0.028 0.382 -0.014 0.282
variety3:factweek3 variety4:factweek3 variety2:factweek4 variety3:factweek4
0.662 0.388 0.228 0.744
variety4:factweek4 variety2:factweek5 variety3:factweek5 variety4:factweek5
0.390 0.402 0.672 0.222 Now let’s compare how model fitness differs among models with no correlation structure (lm1), with AR1 correlation structure (lm2), and with compound symmetry structure (lm3). We will compare these models by using anova() or by the compare_performance() function from the performance library.
anova(sorg_1a, sorg_1b, sorg_1c) Model df AIC BIC logLik Test L.Ratio p-value
sorg_1a 1 23 18.837478 73.62409 13.58126
sorg_1b 2 24 -2.347391 54.82125 25.17370 1 vs 2 23.18487 <.0001
sorg_1c 3 24 20.837478 78.00612 13.58126 Let’s compare the models performance to select a model that fits better.
THESE RESULTS ARE WEIRD
anova(sorg_2a, sorg_2b, sorg_2c, sorg_2d)refitting model(s) with ML (instead of REML)Data: sorghum
Models:
sorg_2d: y ~ variety + factweek + variety:factweek + ar1(0 + week | plot)
sorg_2a: y ~ variety + factweek + variety:factweek + (1 | block/plot)
sorg_2b: y ~ variety + factweek + variety:factweek + ar1(0 + week | block/plot)
sorg_2c: y ~ variety + factweek + variety:factweek + cs(1 + week | block/plot)
npar AIC BIC logLik -2*log(L) Chisq Df Pr(>Chisq)
sorg_2d 22 165.505 222.819 -60.753 121.505
sorg_2a 23 -50.503 9.415 48.252 -96.503 218.01 1 < 2.2e-16 ***
sorg_2b 23 131.602 191.521 -42.801 85.602 0.00 0
sorg_2c 27 -99.302 -28.963 76.651 -153.302 238.90 4 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1We prefer to chose model with lower AIC and BIC values. In this scenario, we will move forward with lm2 model containing AR1 structure.
Let’s look at the model estimates for random and fixed effects.
#tidy(sorg_1b)
sorg_1bLinear mixed-effects model fit by REML
Data: sorghum
Log-restricted-likelihood: 25.1737
Fixed: y ~ variety + factweek + variety:factweek
(Intercept) variety2 variety3 variety4
4.242 0.906 0.646 0.912
factweek2 factweek3 factweek4 factweek5
-0.196 -0.836 -1.156 -1.542
variety2:factweek2 variety3:factweek2 variety4:factweek2 variety2:factweek3
0.028 0.382 -0.014 0.282
variety3:factweek3 variety4:factweek3 variety2:factweek4 variety3:factweek4
0.662 0.388 0.228 0.744
variety4:factweek4 variety2:factweek5 variety3:factweek5 variety4:factweek5
0.390 0.402 0.672 0.222
Random effects:
Formula: ~1 | block
(Intercept)
StdDev: 0.6258308
Formula: ~1 | plot %in% block
(Intercept) Residual
StdDev: 6.827492e-06 0.180349
Correlation Structure: AR(1)
Formula: ~week | block/plot
Parameter estimate(s):
Phi
0.7498238
Number of Observations: 100
Number of Groups:
block plot %in% block
5 20 sorg_2cLinear mixed model fit by REML ['lmerMod']
Formula: y ~ variety + factweek + variety:factweek + cs(1 + week | block/plot)
Data: sorghum
REML criterion at convergence: -72.6014
Random effects:
Groups Name Std.Dev. Corr
plot:block (Intercept) 0.12511 -0.20 (cs)
week 0.02094
block (Intercept) 0.79886 -0.93 (cs)
week 0.05795
Residual 0.07903
Number of obs: 100, groups: plot:block, 20; block, 5
Fixed Effects:
(Intercept) variety2 variety3 variety4
4.242 0.906 0.646 0.912
factweek2 factweek3 factweek4 factweek5
-0.196 -0.836 -1.156 -1.542
variety2:factweek2 variety3:factweek2 variety4:factweek2 variety2:factweek3
0.028 0.382 -0.014 0.282
variety3:factweek3 variety4:factweek3 variety2:factweek4 variety3:factweek4
0.662 0.388 0.228 0.744
variety4:factweek4 variety2:factweek5 variety3:factweek5 variety4:factweek5
0.390 0.402 0.672 0.222 13.1.3 Check Model Assumptions
check_model(sorg_1b, check = c('linearity','qq', 'reqq'), detrend = FALSE, alpha = 0)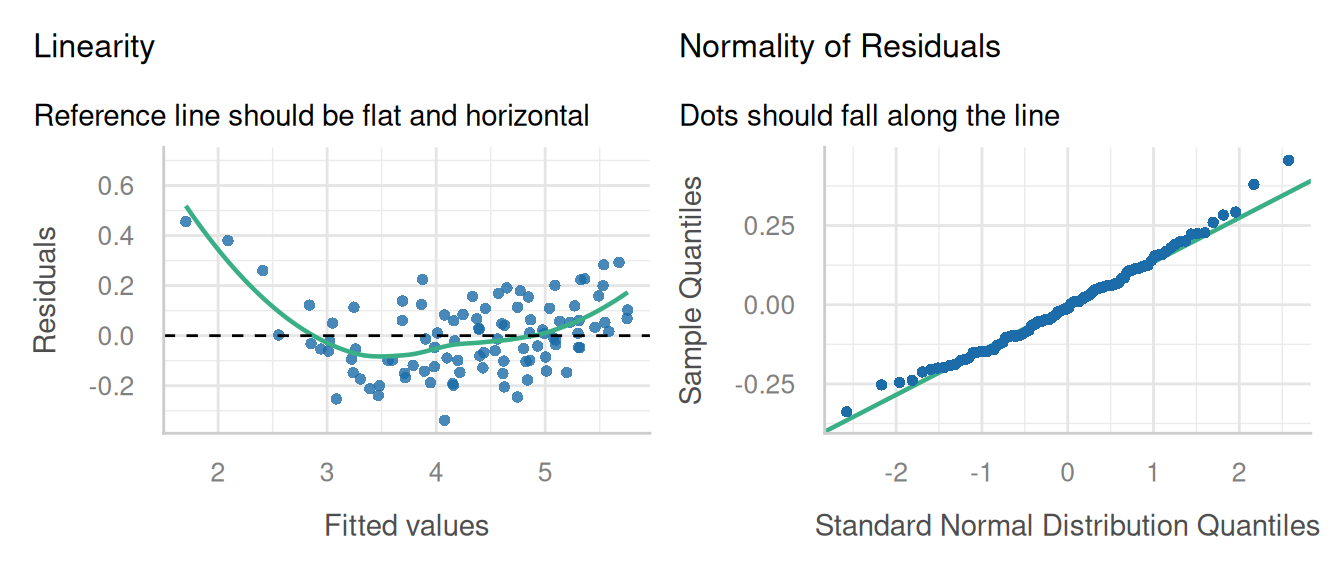
check_model(sorg_2c, check = c('linearity','qq', 'reqq'), detrend = FALSE, alpha = 0)
13.1.4 Inference
anova(sorg_1b, type = "marginal") numDF denDF F-value p-value
(Intercept) 1 64 212.10502 <.0001
variety 3 12 28.28895 <.0001
factweek 4 64 74.79758 <.0001
variety:factweek 12 64 7.03546 <.0001‘lmerTest’ is not loaded because it causes issues with estimation for these particular examples (and perhaps other examples using lme4’s covariance structures).
anova(sorg_2c)Analysis of Variance Table
npar Sum Sq Mean Sq F value
variety 3 1.44900 0.48300 77.331
factweek 4 1.43411 0.35853 57.402
variety:factweek 12 0.94249 0.07854 12.575anova(sorg_2d) # wowAnalysis of Variance Table
npar Sum Sq Mean Sq F value
variety 3 3.9485 1.31618 8.5003
factweek 4 7.9918 1.99796 12.9034
variety:factweek 12 0.7843 0.06536 0.4221The ANOVA table suggests a significant effect of the variety, week, and variety x week interaction effect.
We can estimate the marginal means for variety and week effect and their interaction using emmeans() function.
(mean_1 <- emmeans(sorg_1b, ~ variety))NOTE: Results may be misleading due to involvement in interactions variety emmean SE df lower.CL upper.CL
1 3.50 0.288 4 2.70 4.29
2 4.59 0.288 4 3.79 5.39
3 4.63 0.288 4 3.84 5.43
4 4.61 0.288 4 3.81 5.40
Results are averaged over the levels of: factweek
Degrees-of-freedom method: containment
Confidence level used: 0.95 (mean_2 <- emmeans(sorg_1b, ~ variety*factweek)) variety factweek emmean SE df lower.CL upper.CL
1 1 4.24 0.291 4 3.43 5.05
2 1 5.15 0.291 4 4.34 5.96
3 1 4.89 0.291 4 4.08 5.70
4 1 5.15 0.291 4 4.35 5.96
1 2 4.05 0.291 4 3.24 4.85
2 2 4.98 0.291 4 4.17 5.79
3 2 5.07 0.291 4 4.27 5.88
4 2 4.94 0.291 4 4.14 5.75
1 3 3.41 0.291 4 2.60 4.21
2 3 4.59 0.291 4 3.79 5.40
3 3 4.71 0.291 4 3.91 5.52
4 3 4.71 0.291 4 3.90 5.51
1 4 3.09 0.291 4 2.28 3.89
2 4 4.22 0.291 4 3.41 5.03
3 4 4.48 0.291 4 3.67 5.28
4 4 4.39 0.291 4 3.58 5.20
1 5 2.70 0.291 4 1.89 3.51
2 5 4.01 0.291 4 3.20 4.82
3 5 4.02 0.291 4 3.21 4.83
4 5 3.83 0.291 4 3.03 4.64
Degrees-of-freedom method: containment
Confidence level used: 0.95 (mean_1 <- emmeans(sorg_2c, ~ variety))NOTE: Results may be misleading due to involvement in interactions variety emmean SE df lower.CL upper.CL
1 3.50 0.293 4.26 2.70 4.29
2 4.59 0.293 4.26 3.80 5.38
3 4.63 0.293 4.26 3.84 5.43
4 4.61 0.293 4.26 3.81 5.40
Results are averaged over the levels of: factweek
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 emmeans(sorg_2b, ~ variety) # SE/CI's not estimable (negative variance obtained)NOTE: Results may be misleading due to involvement in interactionsWarning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained! variety emmean SE df lower.CL upper.CL
1 3.50 NaN 1.14 NaN NaN
2 4.59 NaN 1.14 NaN NaN
3 4.63 NaN 1.14 NaN NaN
4 4.61 NaN 1.14 NaN NaN
Results are averaged over the levels of: factweek
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 emmeans(sorg_2d, ~ variety) # dramatic shift in DF and hence CIsNOTE: Results may be misleading due to involvement in interactions variety emmean SE df lower.CL upper.CL
1 3.50 0.23 16.7 3.01 3.98
2 4.59 0.23 16.7 4.10 5.08
3 4.63 0.23 16.7 4.15 5.12
4 4.61 0.23 16.7 4.12 5.09
Results are averaged over the levels of: factweek
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 (mean_2 <- emmeans(sorg_2c, ~ variety*factweek)) variety factweek emmean SE df lower.CL upper.CL
1 1 4.24 0.340 4.24 3.32 5.16
2 1 5.15 0.340 4.24 4.23 6.07
3 1 4.89 0.340 4.24 3.97 5.81
4 1 5.15 0.340 4.24 4.23 6.08
1 2 4.05 0.317 4.29 3.19 4.90
2 2 4.98 0.317 4.29 4.12 5.84
3 2 5.07 0.317 4.29 4.22 5.93
4 2 4.94 0.317 4.29 4.09 5.80
1 3 3.41 0.295 4.36 2.61 4.20
2 3 4.59 0.295 4.36 3.80 5.39
3 3 4.71 0.295 4.36 3.92 5.51
4 3 4.71 0.295 4.36 3.91 5.50
1 4 3.09 0.273 4.45 2.36 3.82
2 4 4.22 0.273 4.45 3.49 4.95
3 4 4.48 0.273 4.45 3.75 5.21
4 4 4.39 0.273 4.45 3.66 5.12
1 5 2.70 0.254 4.58 2.03 3.37
2 5 4.01 0.254 4.58 3.34 4.68
3 5 4.02 0.254 4.58 3.35 4.69
4 5 3.83 0.254 4.58 3.16 4.50
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95
TipRepresenting time variables
It’s common to have two versions of temporary variables in a data set: one coded as numeric and the other being coded as a factor or categorical variable. When modelling, the numeric variable is used for fitting correlation matrix, and a factor/character variable may be used in model statement to evaluate the temporal variable’s effect on the response if you choose to treat it a categorical variable. It is also a valid choice to view a temporal variables as numeric assuming it represents a real time interval. Days and weeks are real time intervals, while “early”, “middle” and “late” are categorical representations of time.
13.2 Split Plot Repeated Measures
Recall that we evaluated the split plot design in Chapter 7. In this example, we will use the same methodology as in Chapter 7 and update it with a repeated measures component.
Next, let’s load an alfalfa intercropping data set. This data is from an irrigation and intercropping experiment which was conducted in southern Idaho. Irrigation is the main plot, intercropping is the split plot, and the in-season alfalfa cutting (“cutting”) is the unit for repeated measures.
alfalfa <- read.csv(here::here("data/alfalfa_intercropping.csv"))This example contains yield data in a split-plot design. The yield data was collected repeatedly from the same Reps over 5 Sample_times. In this data set, we have:
| cutting | time points for data collection |
| irrigation | Main plot, 2 levels |
| plot | experimental unit |
| block | replication unit |
| intercrop | Split plot, 3 levels |
| yield | crop yield |
| row | spatial position by row |
| col | spatial position by column |
13.2.1 Data Integrity Checks
- Check structure of the data
First, we need to look at the class of variables in the data set.
str(alfalfa)'data.frame': 240 obs. of 8 variables:
$ cutting : chr "First" "Second" "Third" "First" ...
$ irrigation: chr "Full" "Full" "Full" "Full" ...
$ plot : int 1101 1101 1101 1102 1102 1102 1103 1103 1103 1104 ...
$ block : int 1 1 1 1 1 1 1 1 1 1 ...
$ intercrop : chr "50A+50O" "50A+50O" "50A+50O" "75A+25O" ...
$ yield : num 221 355 365 289 606 ...
$ row : int 1 1 1 1 1 1 1 1 1 1 ...
$ col : int 1 1 1 2 2 2 3 3 3 4 ...We will now convert the fertilizer and rep to factors. In addition, we need to create a new factor variable (sample_time1) to analyze the time effect.
alfalfa <- alfalfa |>
mutate(cut_num = as.numeric(as.factor(cutting))) |>
mutate_at(c("cutting", "irrigation", "plot", "block"), as.factor)To fit the model, we first need to convert Variety, Fertilizer, and Sample_time to factors. In addition, we need to create a variable for each subject which is a ‘plot’ in this case and contains a unique value for each ‘plot’. The plot variable is needed to model the variation in each plot over the sampling time. The plot will be used as a subject with repeated measures. The subject variable can be either a factor or a numeric but the time (could be year, or sample_time) must be a factor.
- Inspect the independent variables
table(alfalfa$intercrop, alfalfa$irrigation)
Deficit Full
100A 12 12
50A+50F 12 12
50A+50F_AR 12 12
50A+50M 12 12
50A+50M_AR 12 12
50A+50O 12 12
50A+50O_AR 12 12
75A+25F 12 12
75A+25M 12 12
75A+25O 12 12Looks like a balanced design with 2 irrigation treatments and 10 intercropping treatments.
- Check the extent of missing data
colSums(is.na(alfalfa)) cutting irrigation plot block intercrop yield row
0 0 0 0 0 3 0
col cut_num
0 0 - Inspect the dependent variable
Before fitting a model, let’s check the distribution of the response variable.
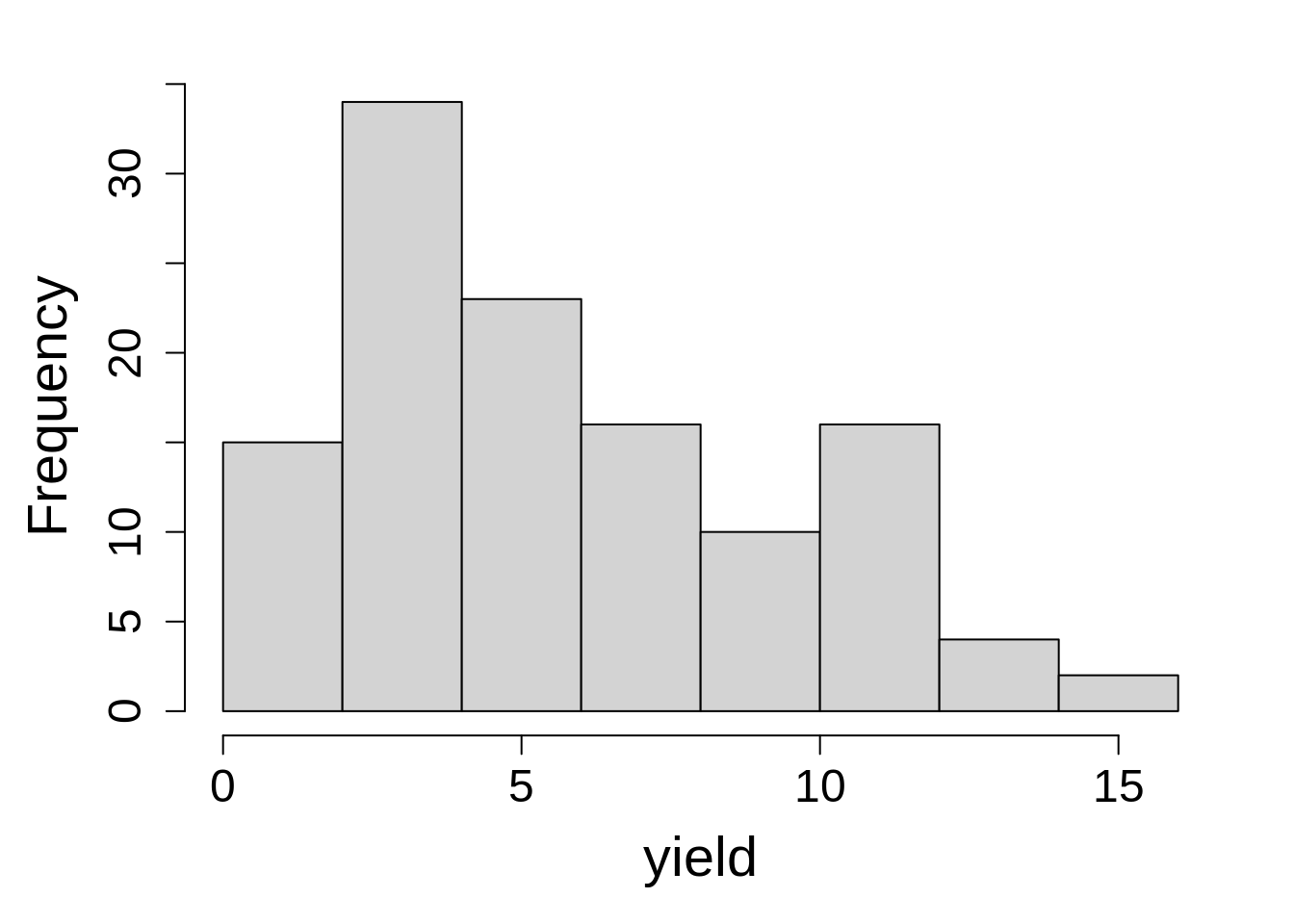
hist(Yield$Yield, xlab = "yield", main = NA)13.2.2 Model fit
For this data set, we will use lme() from ‘nlme’ package and lmer() from ‘lme4’ to fit a linear mixed model with a repeated measures covariance structure. Instead of the summary() function, we will use tidy() function from the ‘broom.mixed’ package to look at estimates of mixed and random effects.
corr_str1 = corAR1(form = ~ cut_num|block/irrigation/intercrop/plot, value = 0.2, fixed = FALSE)
alf_1 <- lme(yield ~ irrigation*intercrop*cutting,
random = ~ 1|block/irrigation/intercrop/plot,
corr= corr_str1,
data = alfalfa, na.action = na.exclude)alf_2 <- lmer(yield ~ irrigation*intercrop*cutting +
ar1(0 + 1|block/irrigation/intercrop/plot),
data = alfalfa, na.action = na.exclude)boundary (singular) fit: see help('isSingular')13.2.3 Check Model Assumptions
We will use check_model() from the performance package to evaluate the model fitness of model fitted using nlme (mod1).
check_model(alf_1, check = c('linearity', 'qq'), detrend = FALSE, alpha = 0)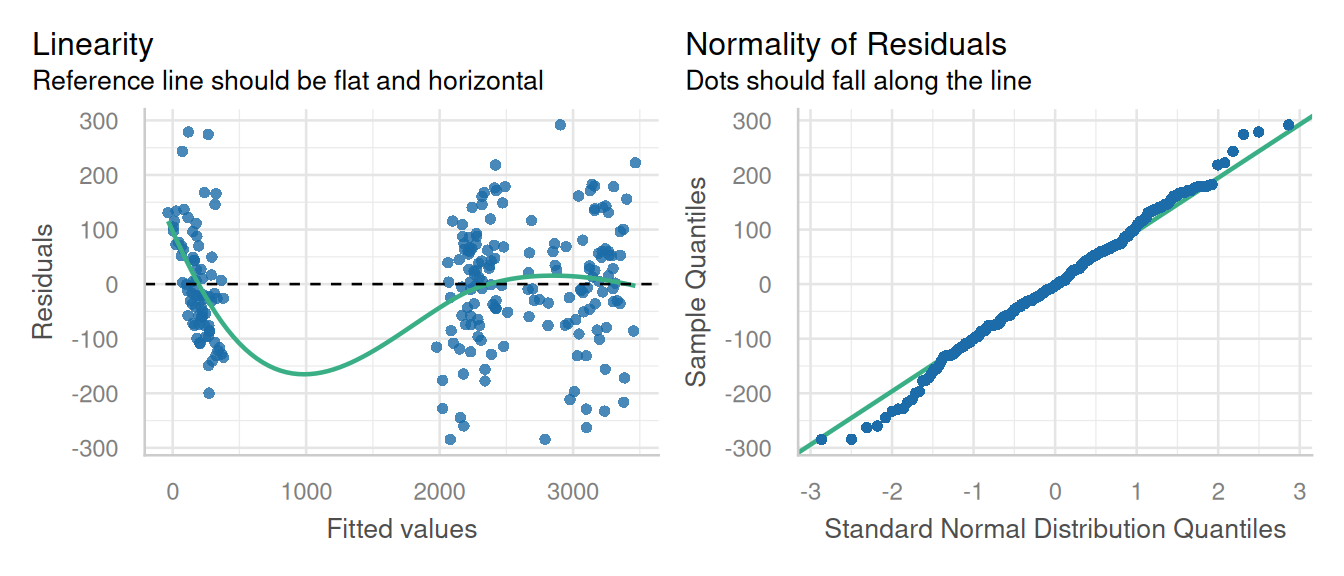
check_model(alf_2, check = c('linearity', 'qq'), detrend = FALSE, alpha = 0)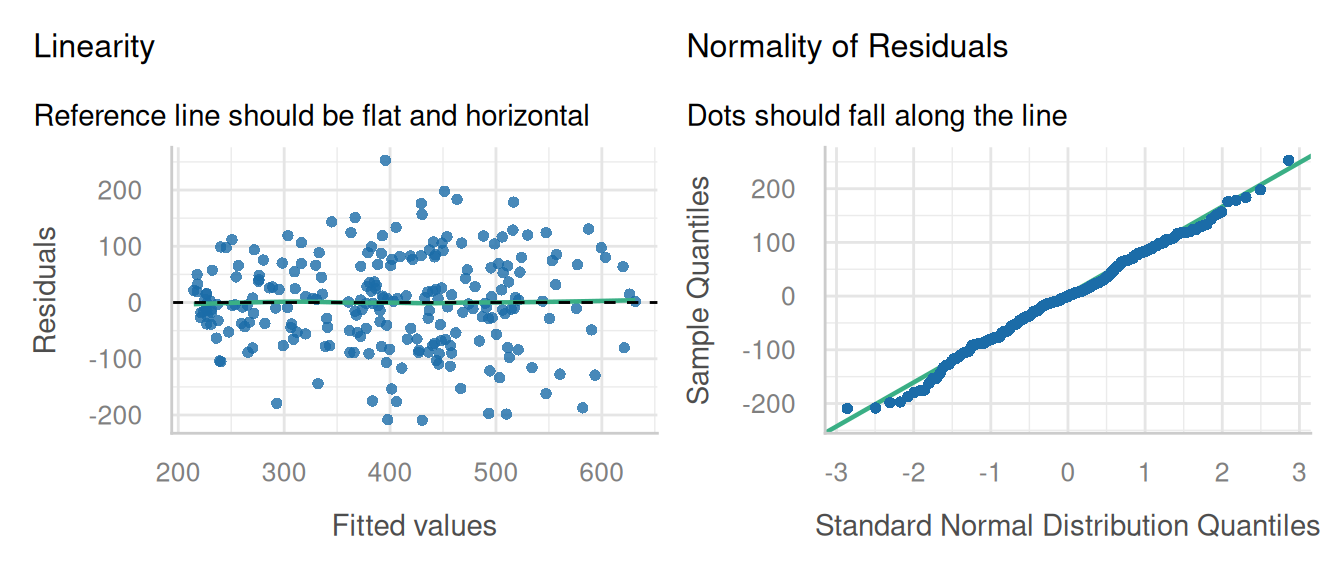
These diagnostic plots look fine. The linearity and homogeneity of variance plots show no trend. The Q-Q plots for the overall residuals and for the random effects fall on a straight line so we can be satisfied with that.
13.2.4 Inference
anova(alf_1, type = "marginal") numDF denDF F-value p-value
(Intercept) 1 115 157.67647 <.0001
irrigation 1 3 0.17409 0.7046
intercrop 9 54 3.25590 0.0031
cutting 2 115 4.24957 0.0166
irrigation:intercrop 9 54 0.68879 0.7158
irrigation:cutting 2 115 0.35554 0.7016
intercrop:cutting 18 115 1.22854 0.2505
irrigation:intercrop:cutting 18 115 0.77391 0.7263anova(alf_2)Analysis of Variance Table
npar Sum Sq Mean Sq F value
irrigation 1 20627 20627 2.3133
intercrop 9 1492996 165888 18.6044
cutting 2 311564 155782 17.4710
irrigation:intercrop 9 80399 8933 1.0019
irrigation:cutting 2 346851 173425 19.4497
intercrop:cutting 18 225400 12522 1.4044
irrigation:intercrop:cutting 18 136500 7583 0.8505Next, we can estimate marginal means and confidence intervals at different levels of the independent variables using emmeans().
emmeans(alf_1,~ cutting)NOTE: Results may be misleading due to involvement in interactions cutting emmean SE df lower.CL upper.CL
First 447 11.3 3 411 483
Second 380 11.4 3 344 416
Third 362 11.5 3 325 398
Results are averaged over the levels of: irrigation, intercrop
Degrees-of-freedom method: containment
Confidence level used: 0.95 emmeans(alf_1,~ intercrop)NOTE: Results may be misleading due to involvement in interactions intercrop emmean SE df lower.CL upper.CL
100A 540 19.0 3 480 601
50A+50F 432 19.5 3 370 494
50A+50F_AR 321 19.0 3 261 381
50A+50M 432 19.0 3 371 492
50A+50M_AR 267 19.0 3 207 328
50A+50O 396 19.5 3 334 458
50A+50O_AR 285 19.0 3 225 345
75A+25F 447 19.5 3 385 509
75A+25M 434 19.0 3 374 494
75A+25O 407 19.0 3 347 467
Results are averaged over the levels of: irrigation, cutting
Degrees-of-freedom method: containment
Confidence level used: 0.95 emmeans(alf_2,~ cutting)Warning: Model has 240 prior weights, but we recovered 237 rows of data.
So prior weights were ignored.NOTE: Results may be misleading due to involvement in interactions cutting emmean SE df lower.CL upper.CL
First 447 9.80 9.38 425 469
Second 380 9.85 9.64 358 402
Third 362 9.91 9.91 340 384
Results are averaged over the levels of: irrigation, intercrop
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 emmeans(alf_2,~ intercrop)Warning: Model has 240 prior weights, but we recovered 237 rows of data.
So prior weights were ignored.NOTE: Results may be misleading due to involvement in interactions intercrop emmean SE df lower.CL upper.CL
100A 540 18.7 39.0 502 578
50A+50F 433 21.4 34.2 390 477
50A+50F_AR 321 20.5 33.5 279 362
50A+50M 432 18.7 39.0 394 470
50A+50M_AR 267 18.7 39.0 229 305
50A+50O 397 19.3 42.4 358 436
50A+50O_AR 285 18.7 39.0 247 323
75A+25F 448 19.3 42.4 409 487
75A+25M 434 18.7 39.0 396 472
75A+25O 407 18.7 39.0 369 445
Results are averaged over the levels of: irrigation, cutting
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 To explore more about contrasts and emmeans please refer to Chapter 13.
13.3 Split-split Plot Repeated Measures
Recall, we have evaluated this split-split plot experiment design in the split-split design chapter. In this example,a repeated measures component will be added to the split-split plot model. This is unpublished data from the PhD Dissertation of Julia Piaskowski.
phos <- read.csv(here::here("data", "split_split_repeated.csv"))| plot | experimental unit |
| block | replication unit |
| Ptrt | Main plot, 2 levels |
| Inoc | Split plot, 2 levels |
| Cv | Split-split plot, 5 levels |
| time | time points for data collection |
| P_leaf | leaf phosphorous content |
13.3.1 Data Integrity Checks
- Check structure of the data
str(phos)'data.frame': 240 obs. of 7 variables:
$ plot : int 1 1 1 2 2 2 3 3 3 4 ...
$ bloc : int 1 1 1 1 1 1 1 1 1 1 ...
$ Ptrt : chr "high" "high" "high" "high" ...
$ Inoc : chr "none" "none" "none" "none" ...
$ Cv : chr "Louise" "Louise" "Louise" "Blanca Grande" ...
$ time : chr "PT1" "PT2" "PT3" "PT1" ...
$ P_leaf: num 3154 2331 247 3016 2160 ...We need two variables for time, one formatted as a factor and the other numeric.
phos1 <- phos |>
mutate(
time = as.factor(time),
time_num = as.numeric(time),
rep = as.character(bloc),
plot = as.character(plot)) - Inspect the independent variables
table(phos1$Cv, phos1$Ptrt, phos1$Inoc) , , = myco
high low
Alpowa 12 12
Blanca Grande 12 12
Louise 12 12
Otis 12 12
Walworth 12 12
, , = none
high low
Alpowa 12 12
Blanca Grande 12 12
Louise 12 12
Otis 12 12
Walworth 12 12Looks like a well balanced design with 2 variety treatments and 3 fertilizer treatments.
- Check the extent of missing data
colSums(is.na(phos1)) plot bloc Ptrt Inoc Cv time P_leaf time_num
0 0 0 0 0 0 0 0
rep
0 No missing values in data.
- Inspect the dependent variable
Before fitting a model, let’s check the distribution of the response variable.
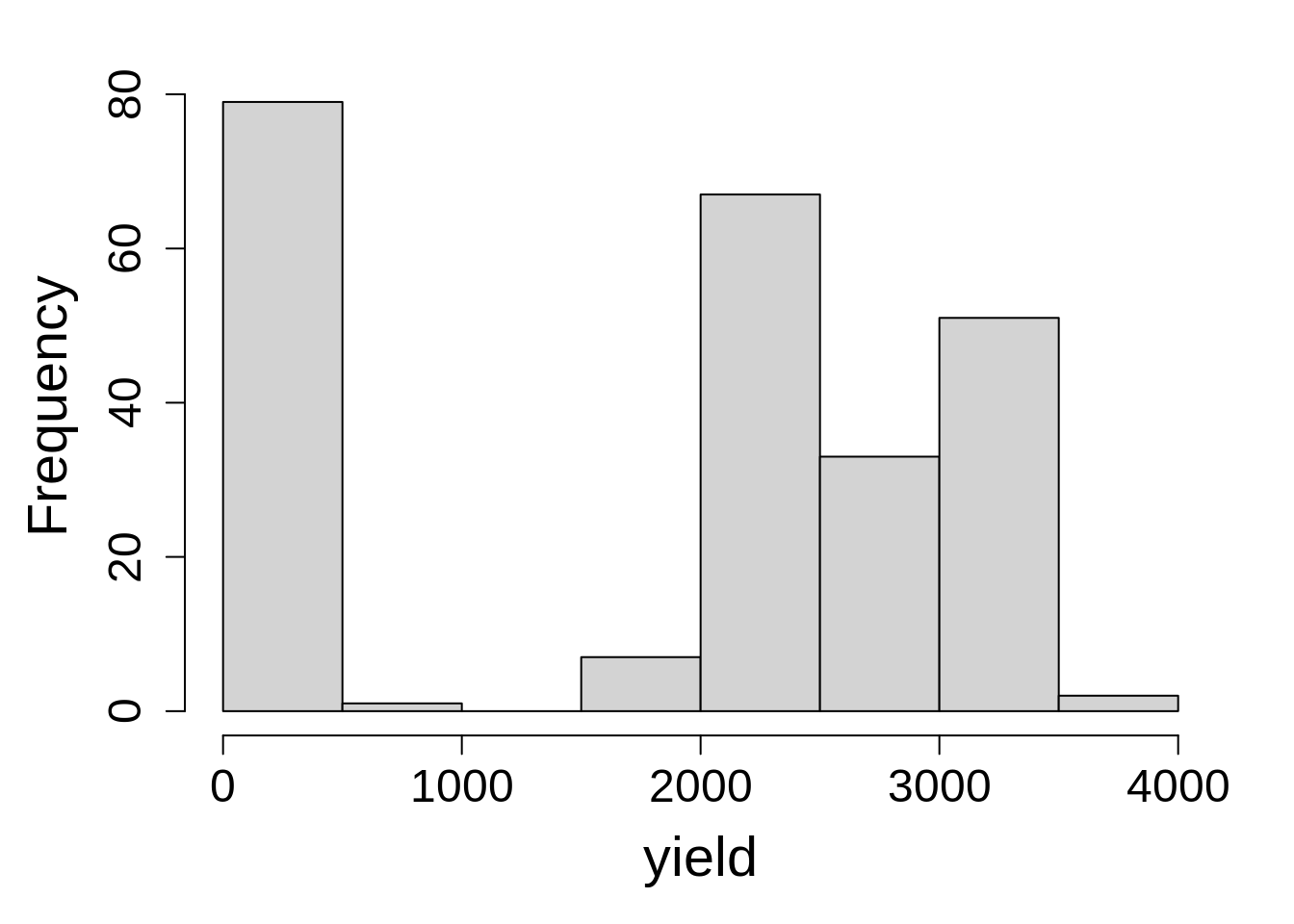
hist(phos1$P_leaf, main = NA, xlab = "P leaf")
boxplot(P_leaf ~ time, data = phos1, main = NA)
Warningdistribution of dependent variables
Note that we observed an uneven distribution of response variable with a bimodal distribution and a noticeable gap in the 500 to 1500 range. Given this odd distribution, it may be tempting to consider a transformation in order to attempt to impose normality. It’s important to remember that the assumption of normality applies to the residuals, not the raw data. Plotting the data is for checking the data looks as expected, a judgment that requires some knowledge of the experiment (this was Julia Piaskowski’s PhD research). In this case, the time points, PT1 and PT2, correspond to early wheat growth stages (tillering and jointing, respectively), and the final time point represents senescent leaf tissue at grain maturity. At that physiological stage, it is normal for phosphorus leaf concentration to be much lower. Since the data look as expected, we will proceed with a general linear model and evaluate the residuals from the model-fitting process when deciding if a non-normal distribution is appropriate for the data.
13.3.2 Model fit
corr_str1 = corCompSymm(form = ~ time_num|rep/Ptrt/Inoc/plot, value = 0.2, fixed = FALSE)
pfit1 <- lme(P_leaf ~ time*Ptrt*Inoc*Cv,
random = ~ 1|rep/Ptrt/Inoc/plot,
corr = corr_str1,
data = phos1, na.action= na.exclude)pfit2 <- lmer(P_leaf ~ time*Ptrt*Inoc*Cv + cs(1|rep/Ptrt/Inoc/plot),
data = phos1, na.action= na.exclude)boundary (singular) fit: see help('isSingular')13.3.3 Check model assumptions
check_model(pfit1, check = c('linearity', 'qq'), detrend = FALSE, alpha = 0)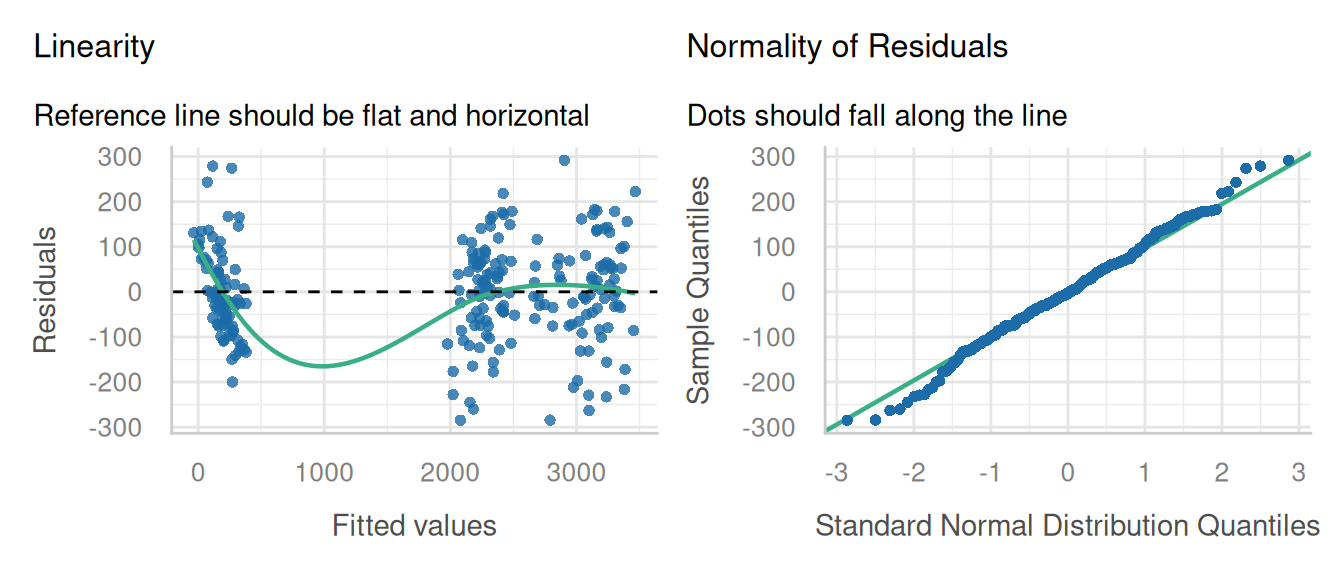
check_model(pfit2, check = c('linearity', 'qq'), detrend = FALSE, alpha = 0)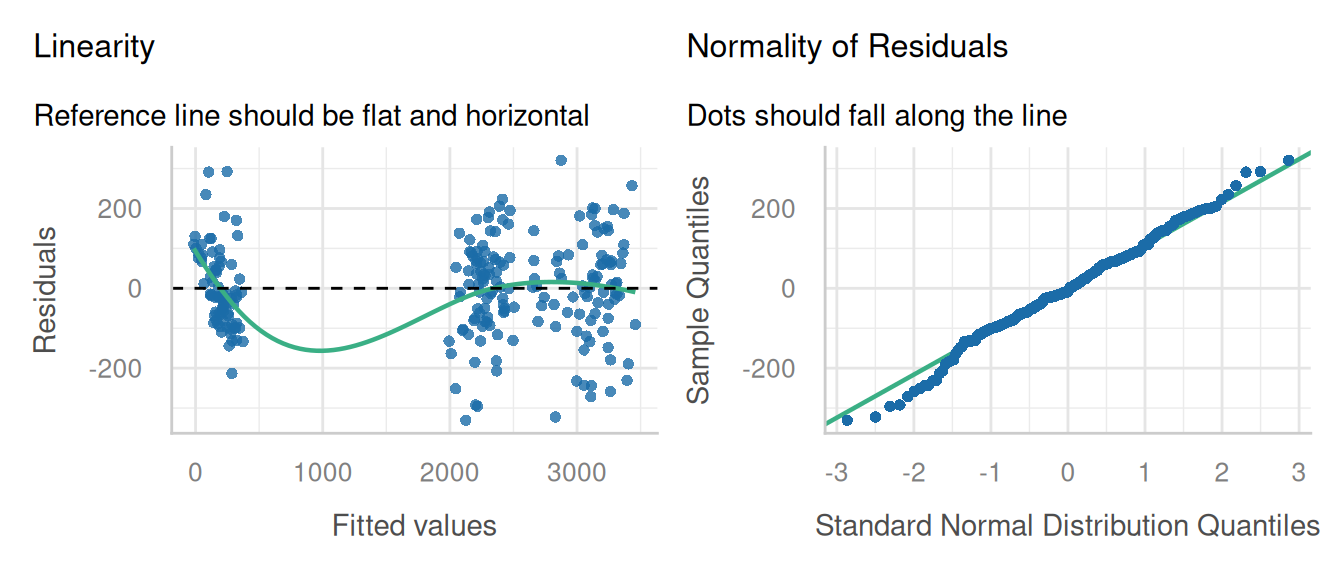
This model fit a first glance is not ideal, but that LOESS line is trying to model a space where there are no data (between 500 and 1500 ppm P leaf concentration), so that can introduce artifacts. Performance does have an option for testing for heteroscedascity:
check_heteroscedasticity(pfit1)Warning in deviance.lme(x, ...): deviance undefined for REML fitOK: Error variance appears to be homoscedastic (p > .999).These results do confirm our suspicions that the residuals were not as heteroscedastic as they first appeared. However, the boxplot indicated a difference in variance for each time point. This issue is addressed in the chapter on variance components.
check_heteroscedasticity(pfit2)Warning: Heteroscedasticity (non-constant error variance) detected (p < .001).13.3.4 Inference
anova(pfit1, type = "marginal") numDF denDF F-value p-value
(Intercept) 1 120 1458.2396 <.0001
time 2 120 518.4432 <.0001
Ptrt 1 3 3.3677 0.1638
Inoc 1 6 1.7697 0.2317
Cv 4 48 7.6028 0.0001
time:Ptrt 2 120 0.6790 0.5091
time:Inoc 2 120 1.9811 0.1424
Ptrt:Inoc 1 6 2.4919 0.1655
time:Cv 8 120 2.4113 0.0189
Ptrt:Cv 4 48 0.5082 0.7299
Inoc:Cv 4 48 2.1349 0.0909
time:Ptrt:Inoc 2 120 0.8410 0.4338
time:Ptrt:Cv 8 120 0.2223 0.9863
time:Inoc:Cv 8 120 0.9462 0.4816
Ptrt:Inoc:Cv 4 48 0.4761 0.7530
time:Ptrt:Inoc:Cv 8 120 0.3886 0.9249anova(pfit2)Analysis of Variance Table
npar Sum Sq Mean Sq F value
time 2 356615427 178307713 9586.7919
Ptrt 1 20863 20863 1.1217
Inoc 1 137849 137849 7.4115
Cv 4 1366765 341691 18.3712
time:Ptrt 2 2936 1468 0.0789
time:Inoc 2 67956 33978 1.8268
Ptrt:Inoc 1 67585 67585 3.6338
time:Cv 8 1581755 197719 10.6305
Ptrt:Cv 4 190763 47691 2.5641
Inoc:Cv 4 103998 25999 1.3979
time:Ptrt:Inoc 2 26957 13478 0.7247
time:Ptrt:Cv 8 11863 1483 0.0797
time:Inoc:Cv 8 231734 28967 1.5574
Ptrt:Inoc:Cv 4 36816 9204 0.4949
time:Ptrt:Inoc:Cv 8 57825 7228 0.3886emmeans(pfit1, ~ Inoc|Cv)NOTE: Results may be misleading due to involvement in interactionsCv = Alpowa:
Inoc emmean SE df lower.CL upper.CL
myco 1832 53 3 1663 2000
none 1904 53 3 1736 2073
Cv = Blanca Grande:
Inoc emmean SE df lower.CL upper.CL
myco 1919 53 3 1750 2088
none 1899 53 3 1730 2068
Cv = Louise:
Inoc emmean SE df lower.CL upper.CL
myco 1876 53 3 1707 2045
none 1898 53 3 1730 2067
Cv = Otis:
Inoc emmean SE df lower.CL upper.CL
myco 1855 53 3 1686 2023
none 1956 53 3 1787 2124
Cv = Walworth:
Inoc emmean SE df lower.CL upper.CL
myco 1667 53 3 1498 1836
none 1737 53 3 1568 1906
Results are averaged over the levels of: time, Ptrt
Degrees-of-freedom method: containment
Confidence level used: 0.95 emmeans(pfit1, ~ time|Cv)NOTE: Results may be misleading due to involvement in interactionsCv = Alpowa:
time emmean SE df lower.CL upper.CL
PT1 3201 56.4 3 3021.89 3381
PT2 2225 56.4 3 2045.20 2404
PT3 178 56.4 3 -1.14 358
Cv = Blanca Grande:
time emmean SE df lower.CL upper.CL
PT1 3183 56.4 3 3003.83 3363
PT2 2334 56.4 3 2154.77 2513
PT3 210 56.4 3 30.28 389
Cv = Louise:
time emmean SE df lower.CL upper.CL
PT1 3121 56.4 3 2941.69 3300
PT2 2366 56.4 3 2186.89 2546
PT3 174 56.4 3 -5.11 354
Cv = Otis:
time emmean SE df lower.CL upper.CL
PT1 3228 56.4 3 3048.98 3408
PT2 2253 56.4 3 2073.98 2433
PT3 234 56.4 3 54.19 413
Cv = Walworth:
time emmean SE df lower.CL upper.CL
PT1 2744 56.4 3 2564.63 2923
PT2 2170 56.4 3 1990.22 2349
PT3 193 56.4 3 13.21 372
Results are averaged over the levels of: Ptrt, Inoc
Degrees-of-freedom method: containment
Confidence level used: 0.95 emmeans(pfit2, ~ Inoc|Cv)NOTE: Results may be misleading due to involvement in interactionsWarning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!Cv = Alpowa:
Inoc emmean SE df lower.CL upper.CL
myco 1832 NaN 1.52 NaN NaN
none 1904 NaN 1.52 NaN NaN
Cv = Blanca Grande:
Inoc emmean SE df lower.CL upper.CL
myco 1919 NaN 1.52 NaN NaN
none 1899 NaN 1.52 NaN NaN
Cv = Louise:
Inoc emmean SE df lower.CL upper.CL
myco 1876 NaN 1.52 NaN NaN
none 1898 NaN 1.52 NaN NaN
Cv = Otis:
Inoc emmean SE df lower.CL upper.CL
myco 1855 NaN 1.52 NaN NaN
none 1956 NaN 1.52 NaN NaN
Cv = Walworth:
Inoc emmean SE df lower.CL upper.CL
myco 1667 NaN 1.52 NaN NaN
none 1737 NaN 1.52 NaN NaN
Results are averaged over the levels of: time, Ptrt
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 emmeans(pfit2, ~ time|Cv)NOTE: Results may be misleading due to involvement in interactionsWarning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!
Warning in .qf.non0(object@V, x): Negative variance estimate obtained!Cv = Alpowa:
time emmean SE df lower.CL upper.CL
PT1 3201 NaN 1.94 NaN NaN
PT2 2225 NaN 1.94 NaN NaN
PT3 178 NaN 1.94 NaN NaN
Cv = Blanca Grande:
time emmean SE df lower.CL upper.CL
PT1 3183 NaN 1.94 NaN NaN
PT2 2334 NaN 1.94 NaN NaN
PT3 210 NaN 1.94 NaN NaN
Cv = Louise:
time emmean SE df lower.CL upper.CL
PT1 3121 NaN 1.94 NaN NaN
PT2 2366 NaN 1.94 NaN NaN
PT3 174 NaN 1.94 NaN NaN
Cv = Otis:
time emmean SE df lower.CL upper.CL
PT1 3228 NaN 1.94 NaN NaN
PT2 2253 NaN 1.94 NaN NaN
PT3 234 NaN 1.94 NaN NaN
Cv = Walworth:
time emmean SE df lower.CL upper.CL
PT1 2744 NaN 1.94 NaN NaN
PT2 2170 NaN 1.94 NaN NaN
PT3 193 NaN 1.94 NaN NaN
Results are averaged over the levels of: Ptrt, Inoc
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95