2 Zen and the Art of Statistical Analysis
Statistical analysis is hard. Despite the common view that science produces unambiguous truths, science and statistics involve making decisions and judgement calls that affect the outcomes and conclusions of a study. These decisions are informed by our scientific thinking and (hopefully) justified in our manuscripts so they can be interrogated by other experts. The (now defunct) website 538 published a well-researched article describing some of these difficulties, the temptation to “p-hack”, and the consequences for scientific research.
This does not mean we should resign ourselves to getting it wrong, but rather we should try our best to approach analysis remembering that the goal is to obtain truth and answer a specific research question, not obtain a low p-value.
The scientific method is the most rigorous path to knowledge, but it’s also messy and tough. Science deserves respect exactly because it is difficult — not because it gets everything correct on the first try. The uncertainty inherent in science doesn’t mean that we can’t use it to make important policies or decisions. It just means that we should remain cautious and adopt a mindset that’s open to changing course if new data arises. We should make the best decisions we can with the current evidence and take care not to lose sight of its strength and degree of certainty. It’s no accident that every good paper includes the phrase “more study is needed” — there is always more to learn.
– Christie Aschwanden/538, Science Isn’t Broken
Below are some things our office frequently says to researchers.
2.0.1 Think About Your Analytical Goals
Throughout this guide, we have tried to explicitly state the goals of each analysis. This helps informs how to approach the analysis of an experiment. It can be difficult, especially for new scientists-in-training (i.e. graduate students), to understand what it is they want to estimate. You may have been handed a data set you had no role in generating and told to “analyze this” with no additional context. Or perhaps you may have conducted a large study that has some overall goals that are lofty, yet vague. And now you must translate the vague aims into clear statistical questions.
It can helpful to think about the exact results you are hoping to get. What does this look like exactly? Do you want to estimate the changes in plant diversity as the result of a herbicide spraying program? Do you want to find out if a fertilizer treatment changed protein content in a crop and by how much? Do you want to know about changes in human diet due to an intervention? What are quantifiable difference or questions that you and/or experts in your domain would find informative and meaningful?
Consider what your study results would look like for (1) the best case scenario where your wildest research dreams come true, and (2) null results, when you find out that your treatment or invention had no effect. It is often very helpful to understand and recognize exactly what both situations look like.
By “consider”, we mean: imagine the final plot or table, or summary sentence you want to present, either in a peer-reviewed manuscript, or some output for stakeholders. From this, you can work backwards to determine the analytical approach needed to arrive at that desired final output. Or you may determine that your data are unsuitable to generate the desired output, in which case, it’s best to ascertain that as soon as possible.
By “consider”, we also mean: imagine exactly what the spreadsheet of results would contain after a successful trial. What columns are present and what data are in those cells? If you are planning an experiment, this can help ensure you plan it properly to actually test whatever it is you want to evaluate. If the experiment is done, this enables you to evaluate if you have the information present to test your hypotheses.
By taking the time to reflect on what it is you exactly want to analyze, this can save time and prevent you from doing unneeded analyzes that don’t serve this final goal. There is rarely one way to analyze an experiment or a data set, so use your limited time wisely and focus on what matters to you most.
2.0.2 Know That Data Cleaning is Time Consuming
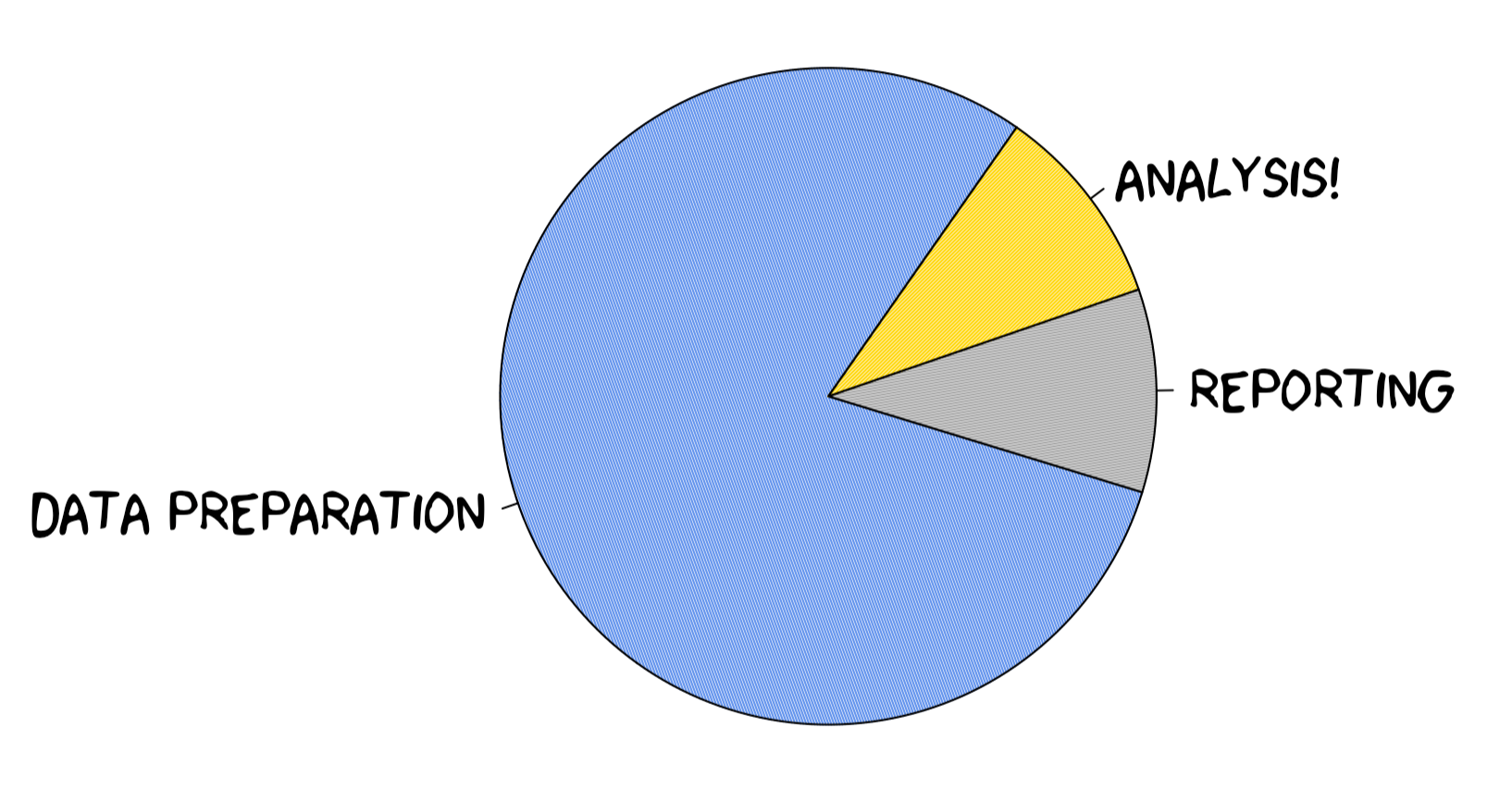
This has and will continue to occupy the majority of researcher’s time when conducting an analysis. Truly, we are sorry for this. But, please know it is not you, it is the nature of data itself. Plan for and prepare yourself mentally to spend time cleaning and preparing your data for analysis. 1. This will likely take way longer than the actual analysis! It is needed to ensure you can actually get correct results in an analysis, and hence data cleaning is worth the time it requires.
1 For an excellent set of basic instructions on data preparation, please see Broman and Woo (2018), Data Organization in Spreadsheets
2.0.3 Interpret ANOVA and P-values with Caution
Informally, a p-value is the probability under a specified statistical model that a statistical summary of the data (e.g., the sample mean difference between two compared groups) would be equal to or more extreme than its observed value.
– American Statistical Association/Wasserstein and Lazar (2016)
The great majority of researchers are deeply interested in p-values. This is not a bad thing per se, but sometimes the focus is so strong it comes at the expense of other valuable pieces of information, like treatment estimates! Russ Leanth, author of the emmeans package, refers to this particular practice as “star gazing”.
It is important to evaluate why you want to do ANOVA, what extra information it will bring and what you plan to do with those results. Sometimes, researchers want to conduct an ANOVA even though the original goals of analysis were reached without it. Running an ANOVA may increase or decrease confidence in your other results. That is not at all what ANOVA is intended to do, nor is this what p-values can tell us. ANOVA compares across group variation to within group variation. It cannot tell us if anything is the ‘same’ (there is a separate branch of analysis, ‘equivalence testing’, for that), and it cannot tell us specifically what is different, unless you are fortunate enough to only have two levels in your treatment structure. P-values provide no guarantee that something is truly different or not; it only quantifies the probability you could have observed these results by chance.
The American Statistics Association recommends that “Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold” (Wasserstein and Lazar 2016). That article also explains what p-values are telling us and how to avoid committing analytical errors and/or misinterpreting p-values. If you have time to read the full article, it will benefit your research!
The main problematic behavior I see is researchers using p-values as the sole criteria on whether to present results: “We wanted to test if x, y and z had an effect. We ran some model and found that that only x had a significant effect, and those results indicate…” (while results with a p-value greater than 0.05 are ignored).
A better option would be to discuss the the results of the analysis and how they addressed the research questions: how did the dependent variable change (or not change) as a result of the treatments/interventions/independent variables? What are the parameters or treatment predictions and what do they tell us with regard to the research goals? And to bolster those estimates, what are the confidence intervals on those estimates? What are the p-values for the statistical tests? P-values can support the results and conclusions, but the main results desired by a researcher are usually the estimates themselves - so lead with that!
To learn more about common pitfalls in interpreting p-values, check out our blog post on the subject and/or Greenland et al. (2016) on the subject.
There is some discussion among statisticians regarding if “null hypothesis significance testing” (hereafter called ‘hypothesis testing’) no longer serves science well. In 2006, Doug Bates (the original author of ‘lme4’) first brought up the underlying foundational challenges of determining the denominator degrees of freedom in a complex mixed model in this infamous listserve post (truly worth a read). For many years, there was no way to obtain p-values from ‘lme4’ model objects unless you were willing to manually calculate them in R. Nowadays, we have ‘lmerTest’ to solve this issue.
Norm Matloff has recently contributed to the discussion by pointing out that all null hypotheses are false, raising the question of why do we continue to pursue this “absurdity” (his word choice). Both of these points of view, while valid, are highly discomforting to most scientists, whose entire discipline may revolve on demonstrating “statistical significance.”
Dushoff et al (2019) also argues the the null hypothesis is nonsensical and that hypothesis testing is frequently misinterpreted. However, they also recognize the centrality of hypothesis testing to scientific publishing, and hence recommend that scientists better acquaint themselves with the foundation concepts of statistical hypothesis testing and shift their language away from the binary “[statistically] significant/not significant” paradigm.
All of this is here to indicate that there is no “one way” to treat hypothesis testing and you may encounters these other views in your career.
2.0.4 Comments on Hypothesis Testing and Usage of Treatment Letters
If you’re going to commit statistical crimes, make sure they are misdemeanors, not felonies.
– Anonymous Statistician
Often, I see researchers use compact letter display (e.g. “A”, “B”, “C”, ….) for indicating differences among treatments. This makes for concise presentation of results in tables and figures, but it can kill statistical power and misses nuance in the results.

Image from a paper published in 2024. Although this was a fully crossed factorial experiment, compact letter display was implemented across all treatment combinations, resulting in some nonsensical comparisons among some more informative contrasts.
Implementing compact letter display can kill statistical power (the probability of detecting true differences) because it requires that all pairwise comparison being made. Doing this, especially when there are many treatment levels, has its perils. One major problem is multiple testing and type 2 error. The RCBD example in this guide has 42 treatment levels, resulting in a total of 861 possible pairwise comparisons (\(=42*(42-1)/2\)), that are then adjusted for multiple testing. With that many tests, a severe adjustment is likely and hence real differences between the levels may not be detected. With so many tests, it could be that there is an overall effect due to treatment, but they all share the same letter!
The second problem is one of interpretation. Just because two treatments or varieties share a letter does not mean they are equivalent. It only means that they were not found to be different. A funny distinction, but alas. There is an entire branch of statistics, ‘equivalence testing’ devoted to just this topic - how to test if two things are actually the same. This involves the user declaring a maximum allowable numeric difference for a variable in order to determine if two items are statistically different or equivalent - something that these pairwise comparisons are not doing.
Another problem is that doing all pairwise comparison may not align with experimental goals. In many circumstances, not every pairwise combination is of any interest or relevance to the study. Additionally, complex treatment structure may necessitate custom contrasts that highlight differences between the marginal estimate of multiple treatments versus another. For example, there may be two levels of ‘high’ nitrogen fertilizer treatment with two different sources (i.e. types of fertilizer). A researcher may want to contrast those two levels together against ‘low’ nitrogen treatment levels.
Often, researchers have embedded additional structure in the treatments that is not fully reflected in the statistical model. For example, a study is looking at five different intercropping mixtures, two that incorporate a legume and three that do not. Conducting all pairwise comparisons only will not estimate the difference due to including a legume in an intercropping mix and not incorporating one. Soil fertility and other agronomic studies often have complex treatment structure. When it is not practical or financially feasible to have a full factorial experiment, embedding different treatment combinations in the main factor of analysis can accomplish this (called an “incomplete factorial”). For some circumstances, this is an excellent experiment design, but compact letter display is an inefficient way to report results from such a study. In such cases, custom contrasts are a better choice for hypothesis testing. The chapter on estimates covers how to do this.
2.0.5 Final Thoughts
Good statistical analysis requires a thoughtful, intentional approach. If you have gone to the trouble to conduct a well designed experiment or assemble a useful data set, take the time and effort to analyze it properly.